


出品|搜狐科技
作者|常博硕、郑松毅
OpenAI与Google,这对“技术宿敌”,在同一日端出了他们的大招。
8月6日凌晨,OpenAI时隔6年发布新开源模型GPT-oss,并首次无保留地开源百亿参数级推理模型;而 Google 则推出了通用智能体生成框架Genie 3,主打“多模态+具身智能”的开源协作平台。
一个深耕语言与推理,一个布局世界模型和行为控制,看似方向不同,实则指向同一场趋势的爆发,谁将真正引领未来的 AI 应用范式?
OpenAI重回开源,推理模型追平o4-mini
今天凌晨,OpenAI官宣了他们的开源模型GPT-oss。这也是OpenAI自GPT-2以来,首次开放完整模型权重。这场由Deepseek引领的大模型开源竞赛,又迎来了一位新的玩家。
据OpenAI创始人兼首席执行官山姆·奥特曼本人表示:“GPT-oss的性能达到o4-mini级别且能在高端笔记本电脑上运行,还有一个更小的模型可以在手机上运行,我为团队感到无比自豪,这是技术上的一大胜利。”
这不仅是OpenAI策略上的重大转变,更是将高性能AI技术带入千家万户的里程碑。简单来说,就是过去只有顶尖科技公司才能玩转的千亿级大模型,现在普通开发者、创业公司乃至个人电脑用户,都有机会亲手体验和使用了。
不过,360创始人周鸿祎今日在会上对搜狐科技等媒体表示,OpenAI并没有从闭源走向开源,发布新的开源模型,是为了应对来自中国公司的挑战压力。
GPT-oss模型采用预训练和后期训练技术进行,特别注重推理能力、效率以及在各种部署环境中的实际应用性。得益于MoE架构,GPT-oss系列实现了性能与效率的完美平衡。此次共发布两款开源模型,分别是GPT-oss-120b和GPT-oss-20b。
GPT-oss-20B的总参数超过200亿,但推理时只激活36亿参数。这意味着,一台配备16GB显存的普通消费级显卡,像4060 Ti都能流畅运行。
而GPT-oss-120B的总参数量高达1170亿,推理时只激活51亿参数。这款模型在基准测试中的表现,甚至可以与OpenAI自家的闭源小模型相媲美,但却能在单张80GB的专业级GPU上部署。
此外,两款模型都原生支持128k的超长上下文窗口,能轻松处理和理解长篇文档、整本小说或海量代码。除此之外,模型还针对智能体工作流进行了特别优化,具备强大的工具调用和逻辑推理能力,能够自主完成更复杂的任务,而不仅仅是简单的聊天。
GPT-oss的训练数据规模达万亿token 级别,以高质量英文为主,覆盖广泛的知识领域和编程语料。虽然英语占比最高,但模型在多语言任务中也表现出色,尤其适合通过轻量化微调强化中文、法语、德语等语言的表现。
为保证安全,OpenAI在训练前进行了生物安全、化学、网络攻击类语料的清洗与过滤,并使用 GPT-4o的内容检测能力进行二次把关。这意味着,GPT-oss在安全性方面也设置了高标准。
GPT-oss系列采用的是最宽松的Apache 2.0开源许可证,允许开发者自由地进行商业使用、修改和分发,无疑是对整个开源AI社区的一次巨大赋能。
在训练侧,GPT-OSS 的训练由OpenAI自研的训练栈支持,在H100 集群上运行,使用了FlashAttention、混合精度计算(fp16/bf16)、大规模并行等一系列前沿技术。训练成本方面,GPT-OSS-120B 总耗时约 210 万 GPU 小时;GPT-OSS-20B 则为其十分之一左右。
同时,模型可根据用户的具体用例和延迟需求,轻松调整推理投入。用户还支持访问完整访问模型的推理过程,从而简化调试并提升输出结果的可信度。同时支持参数级微调,可根据用户的特定用例对模型进行完全定制。在训练时,模型的混合专家(MoE)层便采用了原生的MXFP4精度,使得GPT-oss-120b在单张H100 GPU上即可运行,而GPT-oss-20b仅需16GB内存。
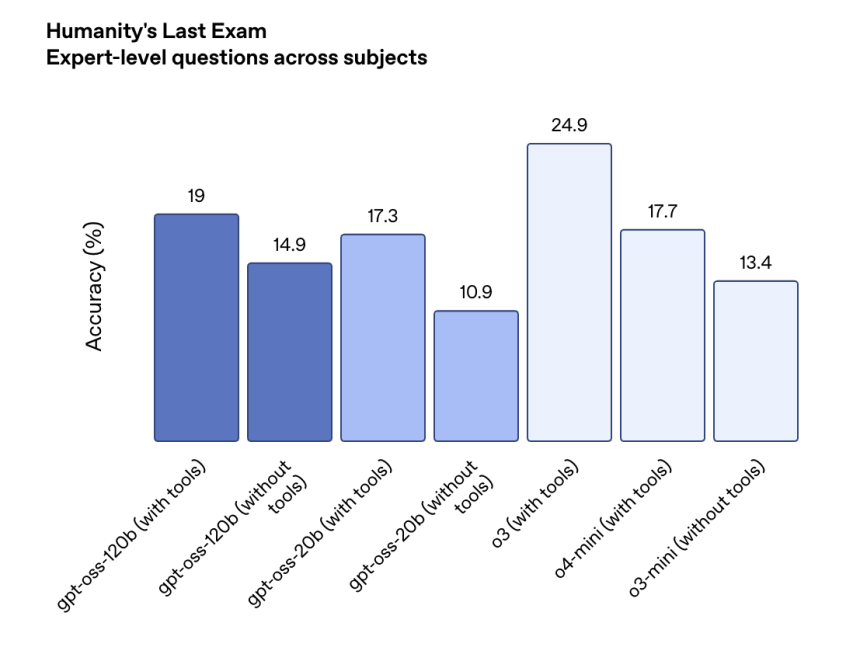
在性能方面,据OpenAI官方数据显示,GPT-oss-120b 在竞赛编程(Codeforces)、通用问题解决(MMLU和HLE)以及工具调用(TauBench)方面表现优于OpenAI o3mini,并与 OpenAI o4-mini 持平或超越性能。
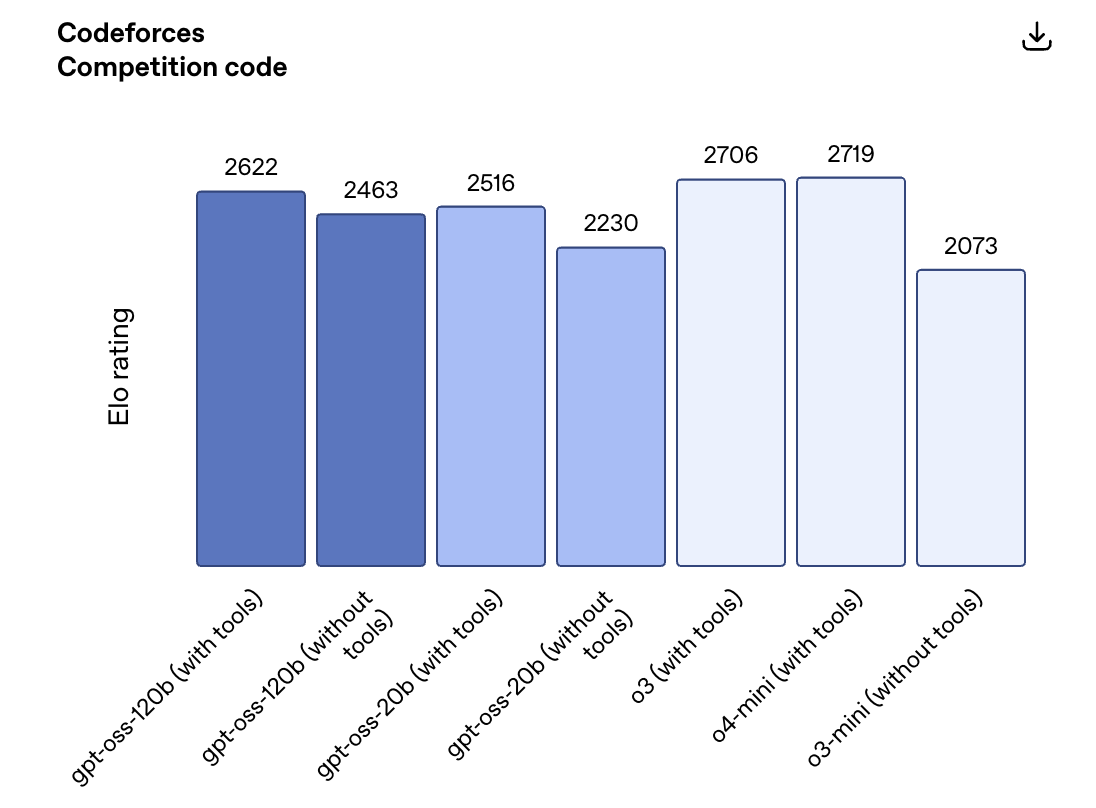
此外,它在相关健康查询(HealthBench )和竞赛数学(AIME 2024 和 2025)方面表现得比 o4-mini 更好。
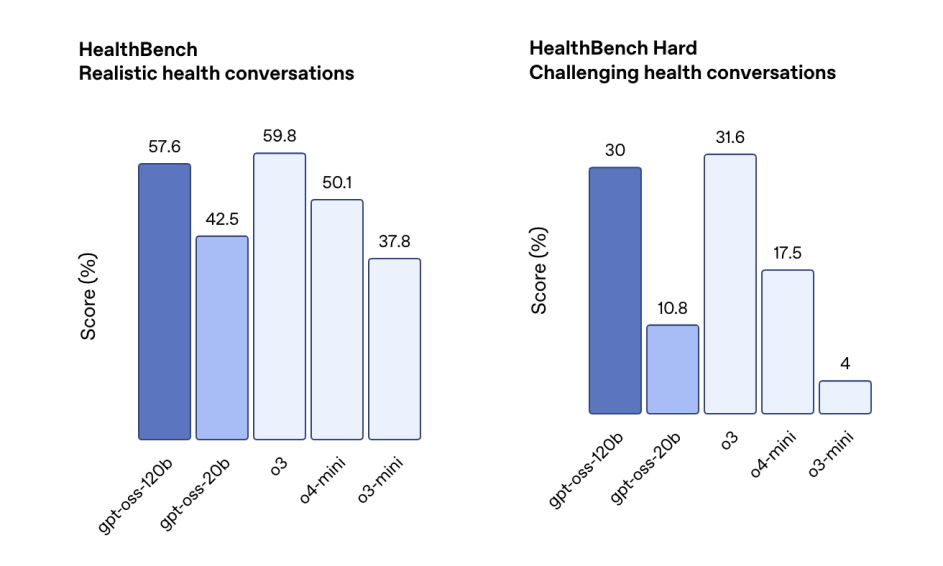
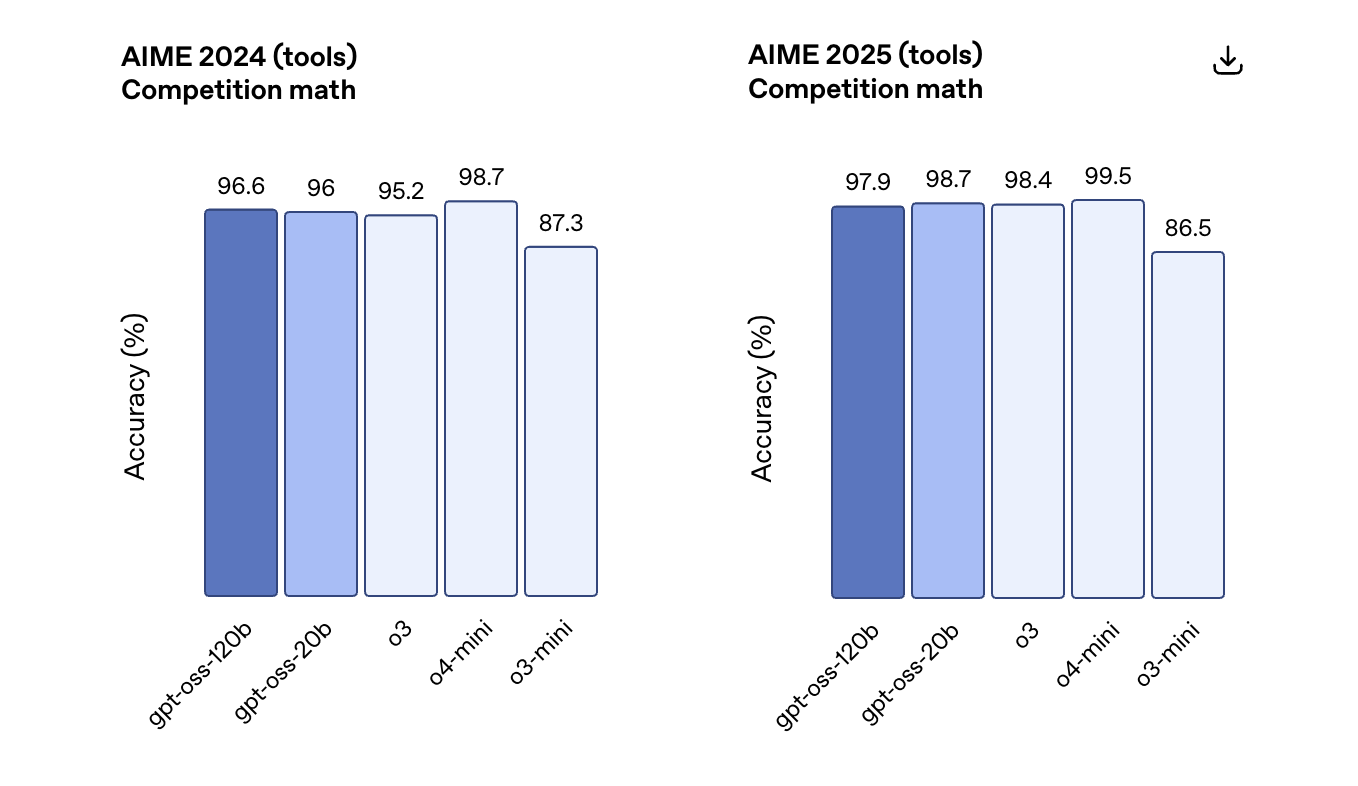
虽然GPT-oss-20b 的规模较小,但在这些相同的评估中,它与 OpenAI o3‑mini 持平,甚至在竞赛数学和医疗方面表现得更好。
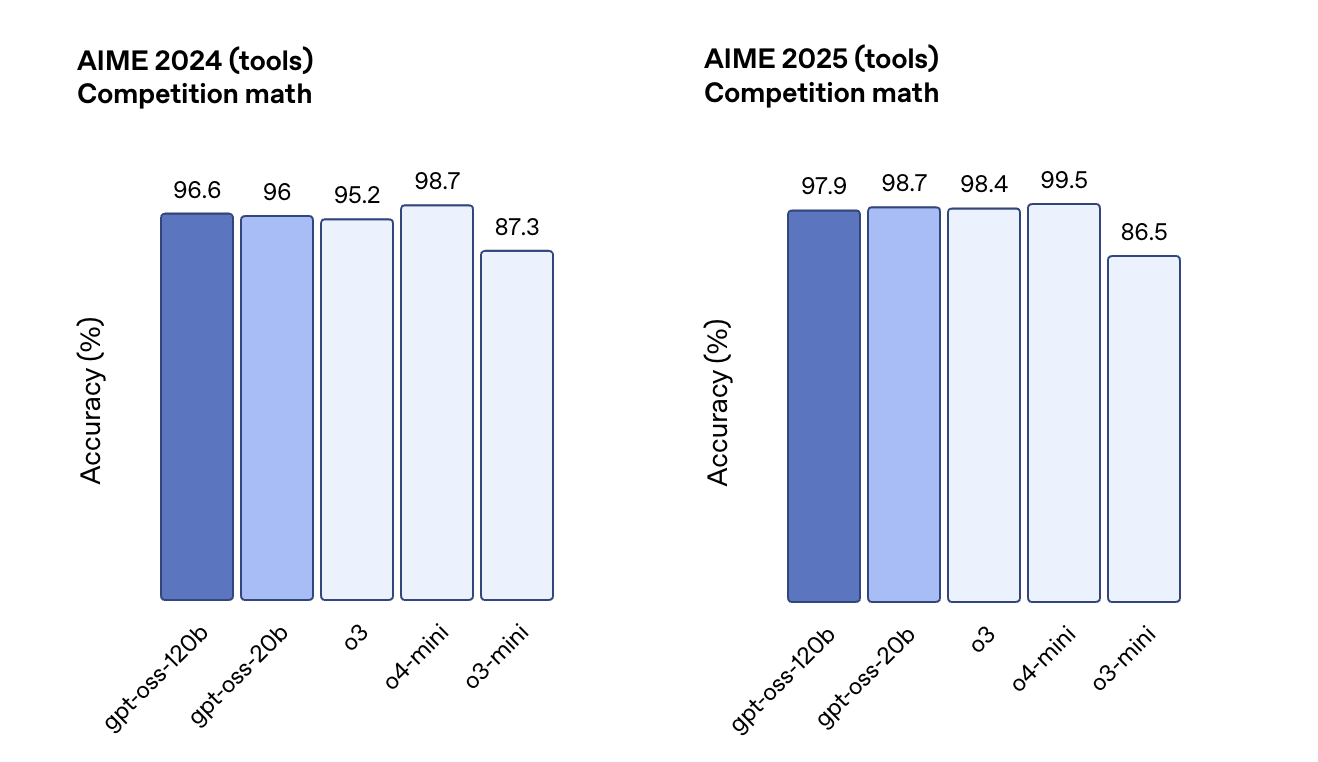
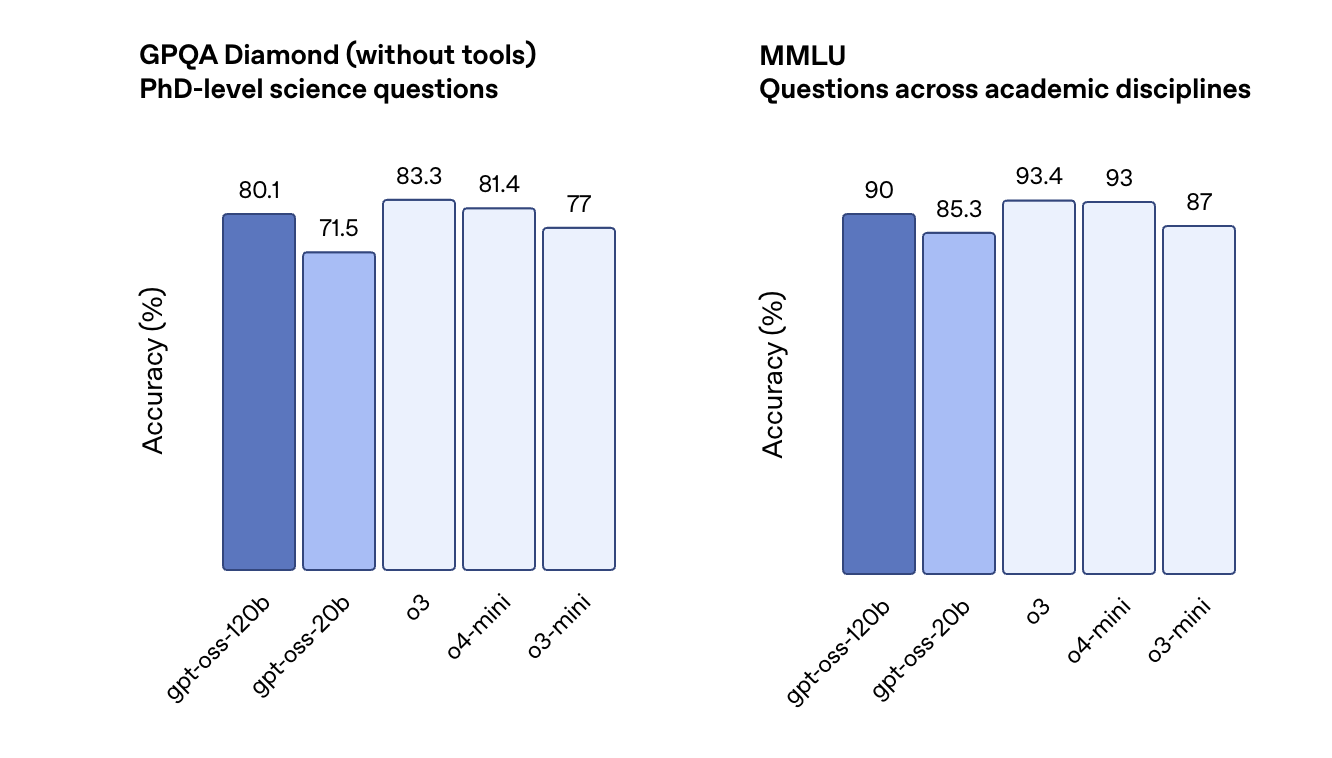
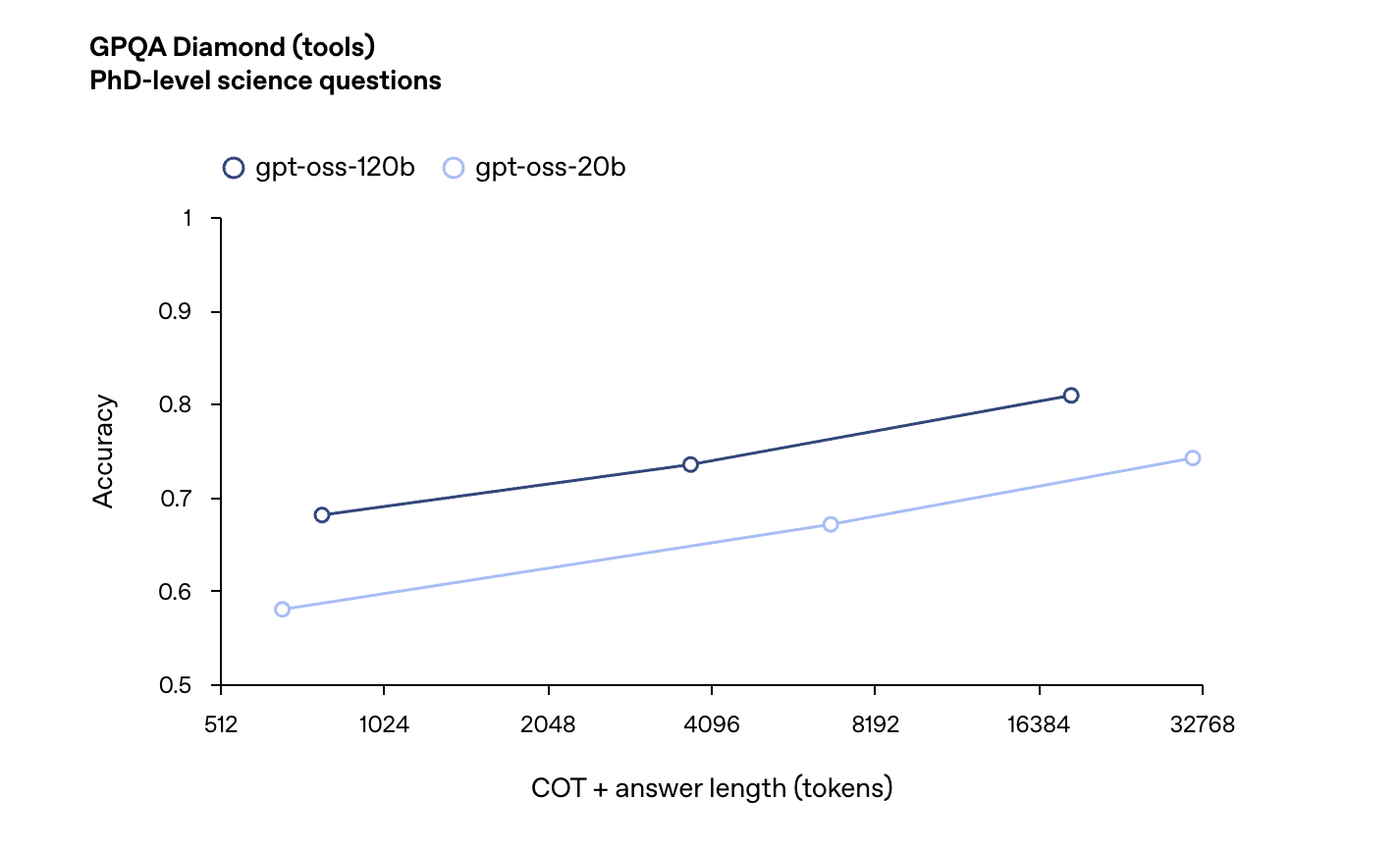
在AIME数学测试中,GPT-oss-120b和GPT-oss-20b随着推理token的增加,准确率折线逐渐逼近。在博士级知识问答基准中,GPT-oss-120b的性能始终领先于GPT-oss-20b。

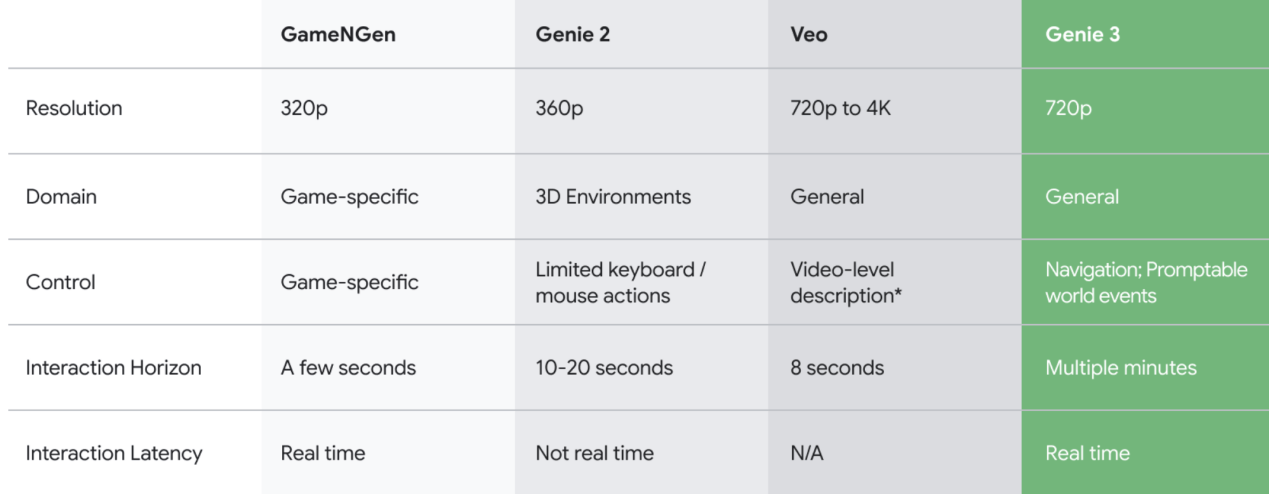
谷歌展示通往AGI的关键世界模型,支持实时交互
反观谷歌,DeepMind正式发布新一代通用世界模型——Genie 3,支持生成前所未有的多样化交互式环境,可谓是当前全球最强“世界AI模拟器”。
一句话(提示文本键入),Genie 3即可生成一个接近真实效果的动态世界。
值得关注的是,Genie 3这次能以每秒24帧的速度,实时生成720p分辨率画面,且首次支持世界模型实时交互,再次推高AI生成领域的天花板。

无论是想改变天气,还是想在世界画面中增加新的角色或物体,通通一句文本命令搞定,将沉浸式体验拉满。
去年,谷歌DeepMind首次放出基础世界模型Genie 1和Genie 2,AI生成世界带来的感官震撼,一时间成为圈内热议的话题。
与前代模型相比,Genie 3对真实物理世界有了更深刻的理解,包括水流、光照等自然现象,以及理解充满生命力的自然系统。
相较于Genie 2,画面一致性和真实感也有了明显提升。

可以说,从Genie到Veo,每一代世界模型的迭代更新,都可以在不同维度看出其能力的进步,不断推动视频生成领域的发展。
谷歌DeepMind研究总监Ali Eslami直言,“这是自ChatGPT以来最令人印象深刻的演示。”
马斯克的评论更为直接,“这就是视频游戏的未来。”
一直以来,“世界模型”被称作是AI的下一个奇点,也被认为是通往AGI终极目标的必经之路。
当大语言模型把“对话”做到极致,下一步比拼的就是谁能先让 AI 真正“理解”世界。也正因此,“世界模型”从学术概念跃升为产业界的“兵家必争之地”。
多年来,谷歌DeepMind坚持在模拟环境领域深耕,引领前沿研究。要真正实现Genie 3的震撼表现,技术团队攻克了诸多难题。
例如为让生成的世界更具真实感,画面没有物理穿模等幻觉现象,就必须让模型在长时间内保持物理上的一致性,考验其物理理解、记忆、延迟等能力。
而良好的实时交互体验来源于语言、图像、控制信号在同一潜空间对齐,任何模态错位都会立即表现为“鬼影”。
尽管如此,Genie 3仍存在一定的局限性:
l 多智能体交互能力不足
在共享环境中准确模拟多个独立智能体之间的复杂交互仍然是一个挑战,目前 Genie 3 难以精确地建模多个智能体之间的互动。
l 地理精度不足
Genie 3生成的环境虽然具有高度的真实感,但仍然是非确定性的,无法精确复现现实中的地理位置。
l 文本渲染效果差
除非在初始提示中明确指定文本内容,否则 Genie 3 生成的文本通常模糊不清。
l 交互时长有限
目前 Genie 3 支持的连续交互时长仅为数分钟,而理想状态下应该能够支持数小时的持续交互。
据谷歌介绍,Genie 3除了为游戏打开新世界大门,现已正式与SIMA平台融合,为机器人和自主系统等 AI 智能体提供广阔的训练空间。
可见,Genie 3的问世,为人类通往AGI的终极目标按下了加速器。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






